Kafka 工作原理
Apache Kafka
官方文档介绍,Kafka 是一个分布式的流平台。实际项目中常用作消息队列。消息队列使用的好处:
-
可以使业务解耦,上下游模块无需关心对方的逻辑实现,若未来有新的需求需要消息时无需改动原有模块内容,仅需建立新消费者组进行消息的消费即可
-
可以实现流量的削峰填谷,实际项目中由于上下游逻辑的复杂度不同,上游服务生产消息的速度可能远大于下游服务消费消息的速度,如果上游服务在短时间内产生大量消息,下游服务很可能因为来不及处理而被压垮,引入消息队列则可以使激增的消息暂存在消费队列中,下游服务根据情况进行消息的消费
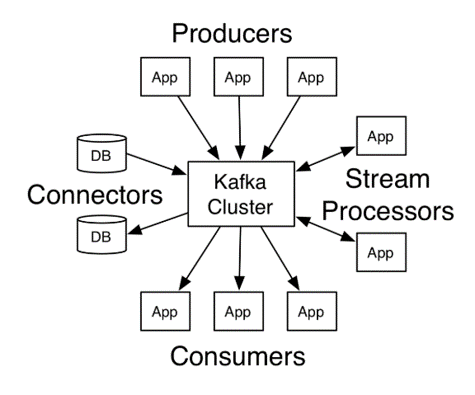
如官方文档的示意图所示,Kafka有四个核心部分:
- Producer 负责生产消息发送给 Kafka 集群
- Consumer 从 Kafka 集群中拉取消息进行消费
- Connector 可以用来监听关系型数据库的更新,也可以将数据同步到其它的数据库
- Stream 可以用来处理 Kafka 消息并发送到其它的 topic
对于消息队列而言,常用的就是 Producer 和 Consumer 这两个部分
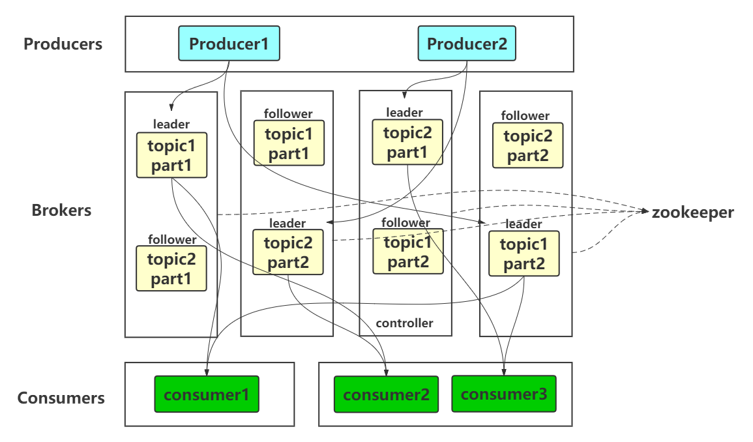
Kafka 中的消息
对于消息队列中的消息,Kafka 引入了 topic 的概念,Producer 将消息发送到合适的 topic,Consumer 根据自身需要订阅相应的 topic。对于一个 topic 下的消息,kafka 又引入了 partition,每个 topic 分为多个 partition,消息通过 随机/轮询/哈希 等方式分布到不同的 partition 实现负载均衡,消费者通过改变 offset 来消费 partition 中的消息。
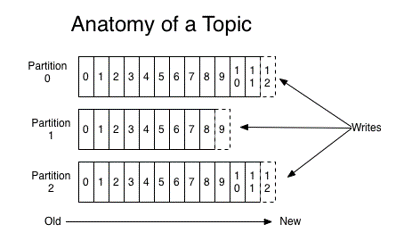
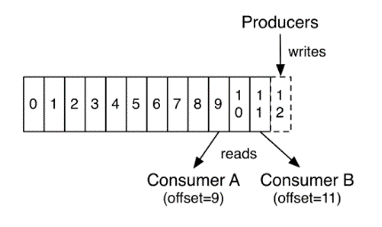
通过 kafka 源码可知,topic 其实只是一个逻辑上的概念,真正的物理结构是 partition:
/**
* A topic name and partition number
*/
public final class TopicPartition implements Serializable {
private static final long serialVersionUID = -613627415771699627L;
private int hash = 0;
private final int partition;
private final String topic;
public TopicPartition(String topic, int partition) {
this.partition = partition;
this.topic = topic;
}
// ...
}
为了保证消息的不丢失,kafka 采取了数据冗余的处理方式,每一个 partition 都有多个副本,但只有其中的 leader 副本负责消息的读写,其余所有的副本(followers)只从 leader 副本同步数据。所以为了负载均衡,一般会将不同 partition 的 leader 副本放在不同的 Broker 上
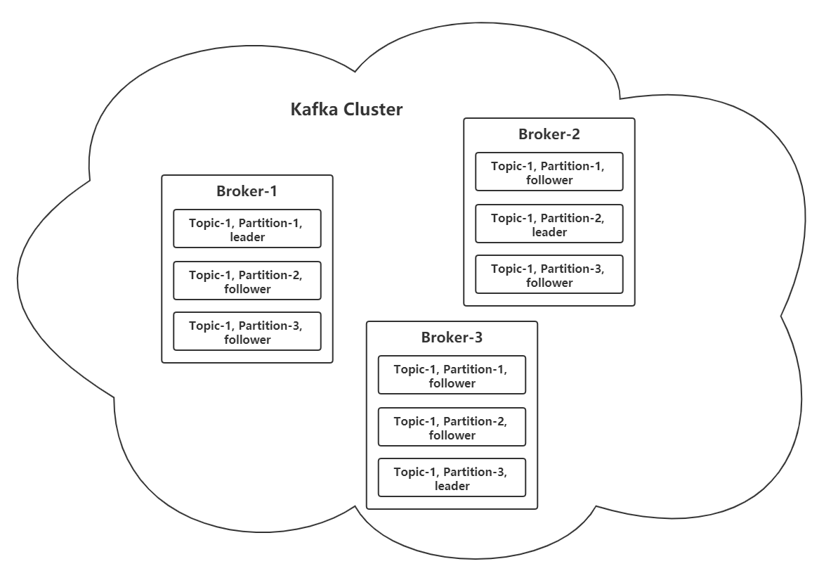
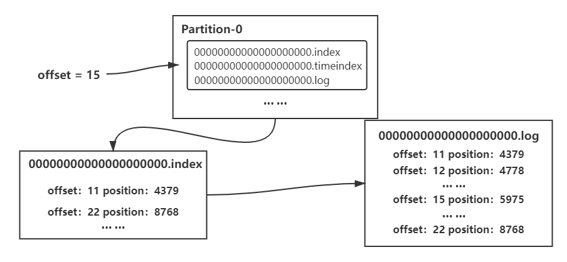
对于消息的存储,Kafka 采用了 segment 的结构,每个 partition 有一个到多个 segment,第一个满了就开启第二个,如图,每个 segment 包含三个文件,其中,.index 文件是索引文件,.log 文件是数据文件,文件名则是该文件起始的 offset 值。
索引文件采用了稀疏索引的方式,win10 命令行窗口下读取 .index 文件,可以观察到 offset 是稀疏索引,其中 position 是物理地址,查看数据文件,可以观察到 offset 和 position 在数据文件中也能对应上。
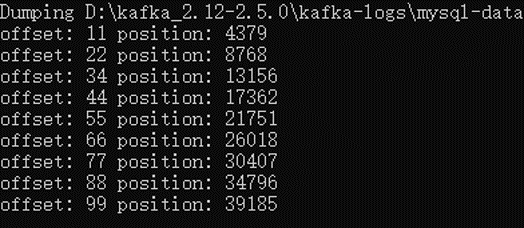
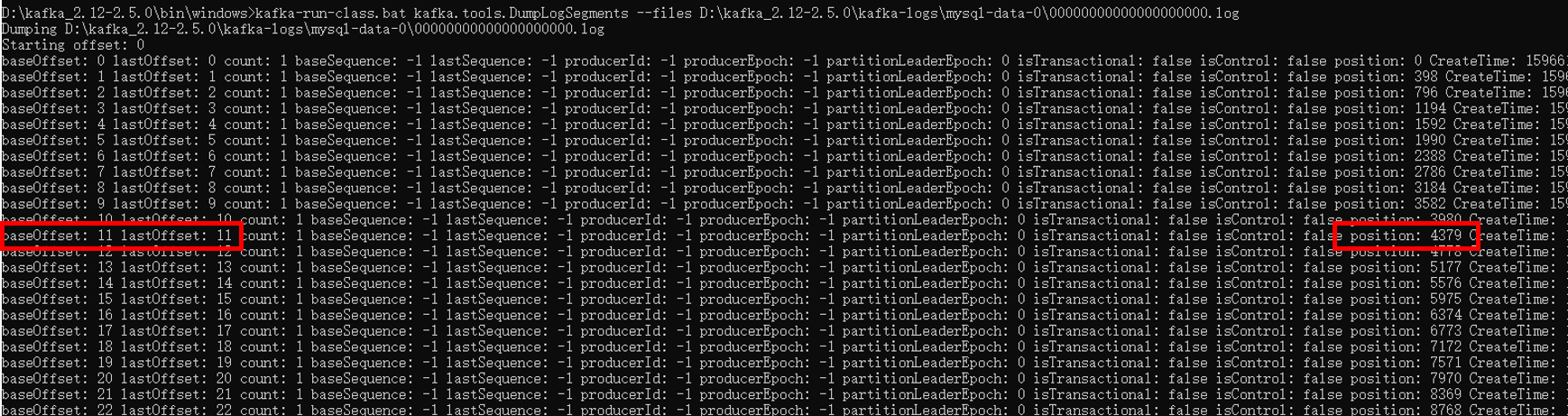
假如现有 offset = 15,现在 .index 文件中查找,可知在 11 和 22 之间,所以相应的物理地址在 4379-8768 之间,再到 .log 文件中按照此范围查找 offset = 15 的消息。
Kafka 服务器 Broker
消息的生产者 Producer
Producer 是 Kafka 中生产消息发送消息的一端,ProducerRecord 定义了 producer 端消息的格式
public class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
// ...
public ProducerRecord(String topic, V value) {
this(topic, null, null, null, value, null);
}
}
其中的构造函数是 ProducerRecord 中最简单的构造函数,即生产者定义一条消息至少需要指定消息的 topic 和消息的内容
KafkaProducer 类定义了 Kafka 生产者,如下是 KafkaProducer 中的一些属性:
public class KafkaProducer<K, V> implements Producer<K, V> {
private final Logger log;
private static final String JMX_PREFIX = "kafka.producer";
public static final String NETWORK_THREAD_PREFIX = "kafka-producer-network-thread";
public static final String PRODUCER_METRIC_GROUP_NAME = "producer-metrics";
private final String clientId;
// Visible for testing
final Metrics metrics;
private final Partitioner partitioner;
private final int maxRequestSize;
private final long totalMemorySize;
private final ProducerMetadata metadata;
private final RecordAccumulator accumulator;
private final Sender sender;
private final Thread ioThread;
private final CompressionType compressionType;
private final Sensor errors;
private final Time time;
private final Serializer<K> keySerializer;
private final Serializer<V> valueSerializer;
private final ProducerConfig producerConfig;
private final long maxBlockTimeMs;
private final ProducerInterceptors<K, V> interceptors;
private final ApiVersions apiVersions;
private final TransactionManager transactionManager;
// ...
}
-
partitioner: 分区器;前面提到 kafka 消息一个 topic 下分为多个 partition,分区器用于决定当前消息发送到具体哪一个分区。DefaultPartitioner 定义了默认情况下的分区算法:
若消息没有 key 值,采取生成随机数并对分区数取余的算法决定分区。
否则通过 murmur2 哈希算法计算 key 值哈希并对分区数取余来决定分区除默认分区器之外,还有轮询等方法来进行分区,也可以通过实现 Partitioner 接口自定义分区器
-
accumulator: 累加器;生产者对于消息的发送并不是每生成一条消息就立即进行发送,而是先保存到累加器中,累积到一定大小或者一定时间间隔再一起发送。
RecordAccumulator 中维护了一个 batches
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;对于生成的消息会根据 TopicPartition 的值存放到对应的队列中
-
sender: Sender 实现了 Runnable 接口,底层是 Java 的 NIO 模型,作为 ioThread 创建的参数传入,当需要发送消息时会唤醒 sender
-
ioThread: 处理 IO 的子线程,在 KafkaProducer 创建的时候会启动该子线程
Producer 有两种发送消息的方法,都是异步发送的,区别在于一个有回调函数一个没有:
public Future<RecordMetadata> send(ProducerRecord<K, V> record)
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
需要对返回值进行处理时可以通过 Future 接收返回值,后期处理时调用 get() 方法获取,或者使用第二种 send() 方法,在回调函数里对返回值进行处理。
对于消息的发送,有一个关键的配置会影响到 Kafka 的性能:request.required.acks
,acks 有三个值:0、1、all(-1);
当 acks = 0 时,表示 Producer 将消息发送过去后就认为发送成功,但有可能因为网络波动使得这次消息并没有发送成功,所以这种设置容易造成消息丢失的发生;
当 acks = 1 时,表示 Producer 将消息发送过去后,若 leader 成功接收后便向 Producer 发送成功接收的信息,若此时 followers 副本还未向 leader 副本进行同步,同时 leader 副本所在 Broker 宕机,也会造成消息丢失的情况发生。
当 acks = -1 时,Producer 发送消息后,要等到所有在 ISR 集合中的副本成功接收消息后,才会收到成功发送的信息,配置未 -1 时,虽然可以最大程度的保证消息不丢失,但是也会带来性能下降的问题,具体使用时应结合使用场景进行配置。